前面幾天分享的內容都是關於如何蒐集跟處理資料,而在資料搜集完畢之後,接下來就要開始標記資料啦!
大家想到資料標記時,可能會想到一個資料列配上一個標記,或是一張圖片配上一個標記。以影片串流服務為主的 Netflix,主要的標記資料型態是影片,並且標記場景也複雜得多。為此,他們建立一個專門的資料標記平台——Marken,提供內部使用者一個能夠有效儲存、管理和搜尋與其媒體數據相關的平台。
讓我們今天一起來認識他吧!
首先,在正式介紹這個平台的功能之前,我們要先認識一下 Netflix 的標記場景,主要分為兩種:
標記每個電影的主題,例如電影 id 1234 是暴力的。這個標記場景相對單純,只要紀錄每部電影的 id、名稱和主題即可。
需要紀錄較多資訊,包含影片中畫面的時間或是空間資訊。
舉例來說,當後製想要重新調整某一個物品的顏色,例如將所有「魷魚遊戲」中所有手套都換一個顏色,這是一個非常浩大的工程,需要標記出所有含有手套的時間點,以及位置。

圖片來源:[1]
另外,我們在前面有介紹過 Netflix Match Cutting 的例子,剪輯人員需要標記出適合作為 frame matching 或 action matching 的影片畫面時間點,
這種複雜場景就需要紀錄較多資訊,包含電影 id、時間或空間資訊,需要進行的操作等等。每一個專案都可能有不同的標記需求,會蒐集到的標記也不盡相同,難以統一格式。
為了滿足這種複雜的需求,Netflix 開發 Marken 以提供標註服務及管理,提供以下功能:
Netflix 的每個團隊都會使用各種機器學習演算法來分析和理解他們的媒體內容,而這些演算法會產生大量不同格式和結構的註釋。因此,Marken 定義一個統一的 schema,無論影片的來源或格式為何,都能夠確保數據有一致的結構,簡化跨團隊和應用程式之間共享和使用註解數據的過程。
Schema 的格式如下,包含註解的型態、位置(boundingBox)和時間資訊(boxTimeRange)。
{
"annotationId": {
"id": "188c5b05-e648-4707-bf85-dada805b8f87",
"version": "0"
},
"associatedId": {
"entityType": "MOVIE_ID",
"id": "1234"
},
"annotationType": "ANNOTATION_BOUNDINGBOX",
"annotationTypeVersion": 1,
"metadata": {
"fileId": "identityOfSomeFile",
"boundingBox": {
"topLeftCoordinates": {
"x": 20,
"y": 30
},
"bottomRightCoordinates": {
"x": 40,
"y": 60
}
},
"boxTimeRange": {
"startTimeInNanoSec": 566280000000,
"endTimeInNanoSec": 567680000000
}
}
}
藉由這種方式,Marken 允許每個團隊註釋任何實體(entity),大家都可以根據自身需求,定義任何客製化 data model,也可以輕鬆添加新的屬性和數據類型以滿足未來需求。在確保數據標記的靈活性與可擴展性的同時,也確保註釋的結構一致性。
另外,Marken 也支援註釋的版本控制,會紀錄註釋的不同版本,以便於了解資料隨時間的變化。
在標記完數據之後,Marken 的另外一項重要功能是能夠滿足複雜的搜尋需求,並且即時又迅速地提供服務。
Marken 需要支援各式各樣的搜尋需求,例如根據時間範圍、空間坐標、文字內容、詞彙關聯性和向量相似性進行搜尋。具體而言,用戶可能會有以下的搜尋需求:
全文檢索:由於用戶可能不知道由畫面被標記的確切標籤,例如,假設標籤是「淋浴簾(shower curtain)」,透過全文檢索,他們可以使用「窗簾(curtain)」來找到與標籤「淋浴簾(shower curtain)」相關的註釋。另外,他們也支援模糊搜尋,或是用戶誤將 curtain 拼成 curtian,還是能夠找到相關內容。
時間註釋搜尋:如果註釋中包含時間範圍,則用戶也可以利用時間搜尋到相關內容。
空間註釋搜尋:影片或圖片中也可以包含空間範圍,例如上述手套的位置,用戶也可以利用 bounding box 的資訊搜尋到相關物體的位置。
語義搜尋:Marken 還可以根據用戶的查詢意圖進行搜尋,簡單來說,用戶的搜尋內容會被轉成向量,再去比對其他最接近的向量,找到文意相近的內容。
搜尋範圍交集:Marken 也支持跨多種類型註釋的範圍交集查詢,用戶可以使用多個數據標籤(由不同演算法產生的不同註釋類型)進行搜尋。舉例來說,當用戶想要尋找「在室內場景中喝酒的 James」,針對這個查詢文字,Marken 會先找到兩個獨立數據標籤(James、室內場景)的結果,以及向量搜尋(飲酒)的結果,然後再提供所有結果的交集。
認識 Marken 所有提供的功能之後,接著,讓我們來看看 Marken 的系統架構是如何設計的吧!
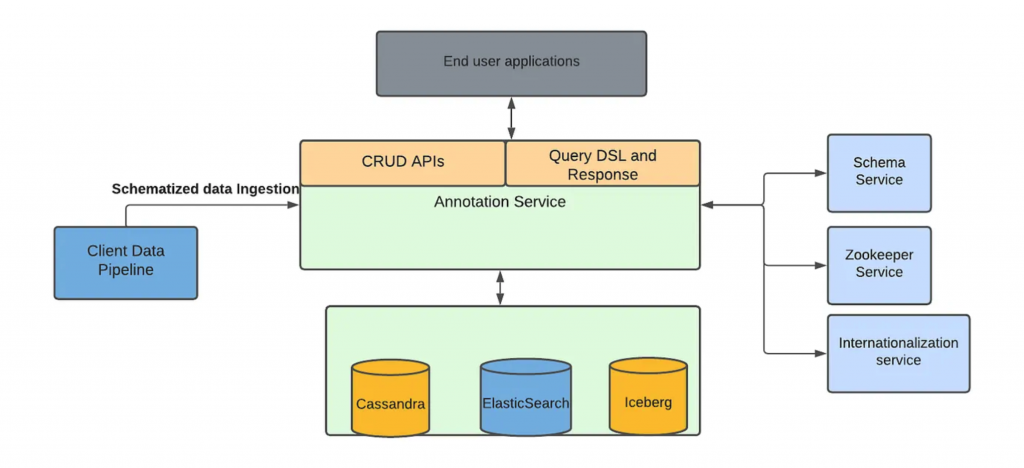
圖片來源:[1]
Marken 的系統設計如上圖所示,主要分為幾個部分:
索引是一種數據結構,其目的是加速查詢過程。當資料被索引到 Elasticsearch 中後,Elasticsearch 會根據資料的內容自動生成適合快速搜尋的索引結構。藉此,每當用戶在搜尋內容時,就可以快速地搜尋相關資料,而不需要逐一掃描整個資料集,大幅提升搜尋速度。
我們今天介紹了 Netflix 複雜的數據標記需求,也介紹他們需要滿足各式各樣的搜尋場景。為此,他們統一了數據註釋的格式,並且打造 Marken,透過 Cassandra 和 Elasticsearch 來建立一個可以
有效儲存、管理和搜尋大量資料的平台。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference:
[1] https://netflixtechblog.com/scalable-annotation-service-marken-f5ba9266d428


 iThome鐵人賽
iThome鐵人賽